4. Elemente von UniScript¶
4.1. Kommentare¶
Kommentare haben den Zweck, ein Programm besser lesbar zu machen. Die Sprache
ignoriert alle Zeichen, die innerhalb von Kommentaren stehen. In UniScript gibt
es Kommentare im C-Stil, die mit den Zeichen
/* anfangen und mit den Zeichen */ enden, sowie Kommentare im C++-Stil,
die mit den Zeichen //
beginnen und bis zum Ende der Zeile reichen. Die Kommentare im C-Stil
können über mehrere Zeilen gehen.
Beispiele:
/*
Dies ist ein Kommentar
im C-Stil.
*/
// Dies ist ein Kommentar
// im C++-Stil
Kommentare im C-Stil können überall dort stehen, wo auch ein Leerzeichen stehen kann, z. B.:
rvSignal = [1.4, 1.45, 133254.4 /* Messfehler ? */, 1.53];
Kommentare im C-Stil dürfen nicht geschachtelt werden. Die Zeichenfolge */
ist also innerhalb eines /* */-Kommentars verboten.
Treffende Namen zu vergeben ist besser als ungünstige Namen zu kommentieren:
ssFilename = GetOpenFileName();
ist auch ohne Kommentar besser zu lesen als die Zeilen
// Dateinamen holen
f = getname();
Auch Selbstverständlichkeiten zu kommentieren ist kein guter Stil
// Minimum des Signals ermitteln
rsMin = min(rvSignal);
Kommentare werden häufig dazu verwendet, Quellcode-Zeilen auszublenden wie im folgenden Beispiel:
// Berechnung einer n mal n Hilbert-Matrix
def hilb(n)
{
/*
h = zeros(n, n);
for (i in 1:n) {
for (j in 1:n) {
h[i;j] = 1/(i+j-1);
}
}
return h;
*/
// so geht es schneller als
// mit zwei geschachtelten for-Schleifen
x = 1:n;
x = x[ones(1,n); /* alle Spalten */ ];
return 1./(x+x.'-1);
}
4.2. Fortsetzungszeilen¶
In UniScript dürfen Anweisungen nicht über mehrere Zeilen gehen. Wird eine Anweisung zu lang, kann man mit zwei Punkten eine Fortsetzungszeile einleiten. UniScript ignoriert alle Zeichen hinter den beiden Punkten bis zum Ende der Zeile:
return (ones(1,m) .* 10) .^ ..
[s1+(0:m-2) * (S2-s1) ./ (m-1), S2];
Fortsetzungszeilen können nur dort beginnen, wo auch ein Leerzeichen erlaubt ist, also nicht innerhalb von Namen oder Konstanten.
Eine Zeichenkette kann folgendermaßen in mehreren Zeilen geschrieben werden:
"Dies ist eine lange konstante Zeichenkette," + ..
" die über zwei Zeilen geschrieben wird"
Ab UniPlot R2013.11 brauchen hinter einem Komma, einem Semikolon und binären
Operatoren keine .. mehr angegeben werden. D. h. die .. in den beiden
Beipielen oben sind redundant.
4.3. Konstanten¶
Die einfachste Form eines Ausdrucks ist eine Konstante. In UniScript gibt es drei konstante Typen: Reelle Konstanten, komplexe Konstanten (diese beiden Typen bezeichnet man als numerische Konstanten) und Zeichenketten-Konstanten oder String-Konstanten.
4.4. Numerische Konstanten¶
Eine numerische Konstante steht für eine Zahl. In UniScript werden Zahlen als doppelt genaue Fließkomma-Zahlen gespeichert.
Beispiele für gültige Zahlen sind:
123
12.8
+13.01e-3
12E3
Nicht zulässig sind folgende Darstellungen
.03 // Punkt am Anfang nicht erlaubt
12. // Punkt am Ende nicht erlaubt
13.9D8 // Buchstabe D als Exponentkennzeichen
// nicht erlaubt
3,82 // Dezimaltrennzeichen ist der Punkt,
// nicht das Komma
Es gelten genau die gleichen Regeln wie bei der Programmiersprache C.
Normalerweise wird man Konstanten einen Namen geben. Dazu wird wie in C die
#define-Anweisung verwendet. Die #define-Anweisung hat folgende Form:
#define konstanten-name ersatztext
Anmerkung für C-Programmierer: Die define-Anweisung ist die einzige
Präprozessor-Anweisung, die UniScript kennt. Parameter sind nicht zulässig.
Immer dort, wo der UniScript-Interpreter auf konstanten-name trifft (außer
in Zeichenketten und Kommentaren), wird er durch den Ersatztext ausgetauscht.
Der Konstanten-Name muss den Regeln für UniScript-Namen gehorchen, der Ersatztext
kann eine beliebige Zeichenfolge sein.
Wird beispielsweise die Konstante PI wie folgt definiert:
#define PI 3.1415926535897931
kann der Name PI in Ausdrücken wie u = 2 * PI * r
verwendet werden. Die Namen von Konstanten werden üblicherweise in
Großbuchstaben geschrieben, um sie leichter von Variablennamen zu
unterscheiden.
Nach der Definition des Namens PI ist der Name in allen Dateien
bekannt, nicht nur in der Datei, in der er definiert wurde wie in der
Programmiersprache C.
4.5. Hexadezimale und oktale Konstanten¶
Ganzzahlige Konstanten können wie in C auch in hexadezimaler oder oktaler Schreibweise geschrieben werden.
Besteht eine Zeichenkette aus den Zahlen 0 ... 9 und a ... f (oder
A ... F) und beginnt sie mit den Zeichen 0x oder 0X, wird sie als
hexadezimale Zahl (Basis 16) interpretiert. Beispiel:
0x10 ist 16
0xFF ist 255
0x0d ist 13
0x5 ist 5
Besteht eine Zeichenkette nur aus den Ziffern 0 ... 7, und sie beginnt mit
der Ziffer 0 (null) wird sie als oktal, also zur Basis 8, interpretiert.
034 ist 28
0377 ist 255
4.6. Komplexe Konstanten¶
Komplexe Konstanten werden eingegeben, indem man den Kleinbuchstaben i
direkt hinter die Zahl schreibt, z. B. 3i, 1.23e-8i, 0xFFi.
4.7. String Konstanten¶
String-Konstanten sind in Anführungszeichen stehende Zeichenketten:
"Dies ist eine String-Konstante"
Ein String kann Steuerzeichen (Escape Sequenzen) für die Ausgabe enthalten. Will
man z. B. bei der Ausgabe das Wort "String-Konstante" in eine neue Zeile
schreiben, muss man vor das Wort den String \n einfügen:
"Dies ist eine\nString-Konstante"
UniScript kennt folgende Escape-Sequenzen:
| Code | Bedeutung |
|---|---|
\ |
Repräsentiert ein einzelnes \-Zeichen (den Backslash) |
\n |
Repräsentiert einen Zeilenwechsel (newline) |
\r |
Repräsentiert einen Wagen-Rücklauf (carriage return) |
\b |
Repräsentiert ein backspace |
\f |
Repräsentiert ein formfeed |
\t |
Repräsentiert ein Tabulator-Zeichen |
\a |
Repräsentiert einen Warn-Ton (allert) |
\" |
Repräsentiert das Zeichen \" |
\zzz |
zzz steht für eine ganze Zahl in hexadezimaler, oktaler oder dezimaler Schreibweise (siehe Anmerkung). |
\uXXXX |
XXXX steht für eine hexadezimale Zahl mit genau 4 Ziffern, die den Code eines Unicode-Zeichens enthalten (ab UniPlot 5.0). |
Anmerkung: Die Zahl zzz kann in dezimaler, hexadezimaler oder oktaler
Schreibweise im Bereich 0 ... 255 (dezimal) sein. Es wird der
ASCII-Code für die entsprechende Zahl ausgegeben. Beispielsweise sind
die Zeichenketten "Hallo\n", "Hallo\10" (dezimal),
"Hallo\012" (oktal) und "Hallo\x0a" oder "Hallo\0x0a" identisch.
Bei der hexadezimalen Schreibweise, müssen den Zeichen \x oder \0x
exakt zwei hexadezimale Zeichen (0 .. f) folgen.
Bei der dezimalen oder oktalen Schreibweise werden alle dezimalen (0 .. 9)
oder oktalen (0 .. 7) Ziffern gelesen. Falls die Zahl größer als 255 (dezimal)
ist, wird sie durch Abschneiden auf ein Byte gekürzt. Beispielsweise ist
"\300a" nicht das selbe wie "\30" + "0a". Die hexadezimale Schreibweise
ist der dezimalen und oktalen Schreibweise vorzuziehen, da sie nicht zu solchen
Missverständnissen führen kann.
Falls eine Zeichenkette den Präfix r hat, z. B. r"Hallo\10" werden
alle Backslashe in der Zeichenkette belassen, r"Hallo\10" liefert die
selbe Zeichenkette wie "Hallo\\10". Innerhalb einer einfachen
Zeichenkette mit r-Präfix kann kein "-Zeichen definiert werden.
4.8. „Lange“ Zeichenketten¶
Ab UniScript 4.0 gibt es sogenannte „lange Zeichenketten“. Diese Zeichenketten
beginnen mit der Zeichenfolge
"[[ und enden mit der Zeichenfolge ]]".
Beispiel:
a = "[[
Dies ist eine
String-Konstante
]]"
ist die selbe Zeichenkette wie:
a = "\nDies ist eine\nString-Konstante\n"
In langen Zeichenketten können "-Zeichen mit oder ohne führendem Backslash
verwendet werden. Wenn r als prefix benutzt wird verliert der Backslash seine
Spezialbedeutung und wird zu einem normalen Zeichen. Das kann zum Beispiel für
Dateinamen nützlich sein.
b = r"[[
c:\foo
\t
]]"
// b == "\nc:\\foo\n\\t\\n"
4.9. Null-Zeichen in Strings¶
Ab UniScript 4.2.0 können Zeichenketten Null-Zeichen enthalten (eight-bit clean
Strings). Dadurch können UniScript-Strings beliebige binäre Daten enthalten.
Der +-Operator kann auch für Zeichenketten mit 0-Zeichen verwendet werden.
Die Vergleichsoperatoren verwenden nur den String bis zum ersten 0-Zeichen.
"Hello\x00Hello" == "Hello"
liefert TRUE (1). Um die Zeichenketten komplett zu vergleichen, kann die Funktion mem_compare verwendet werden.
Viele String-Funktionen verwenden nur den Teil des Strings bis zum ersten 0-Zeichen. Beispiel:
strlen("Hello\x00Hello")
liefert 5, d. h. die Anzahl an Zeichen bis zum ersten Null-Zeichen.
Der Funktionsaufruf mem_len("Hello\x00Hello") liefert in UniPlot 4.x den
Wert 11 in UniPlot 5.x oder höher den Wert 22, da UniPlot 5 Unicode verwendet und
ein Unicode-Zeichen 2 Bytes enthält.
4.10. Variablen¶
Eine Variable ist eine benannte Speicheradresse. In UniScript braucht eine Variable nicht deklariert werden, man kann sie einfach bei Bedarf definieren:
a = 1
Falls a bisher noch nicht existierte, wird sie durch diese
Anweisung erzeugt, das heißt, es wird Speicherplatz für die 1
bereitgestellt und die 1 wird in den Speicher kopiert. Falls die
Variable a bereits vorher existierte, wird zunächst der alte
Wert der Variablen gelöscht. Der alte Wert kann z. B. ein
"String" gewesen sein, die Variable kann also ihren Typ ändern.
Der Name einer Variablen kann aus Buchstaben, Ziffern und
Unterstrichen bestehen. Er muss aber mit einem Buchstaben oder einem
Unterstrich anfangen. Länderspezifische Buchstaben (z. B. Umlaute) sind
nicht erlaubt. Namen können beliebig lang sein. Es werden jedoch nur
die ersten 80 Zeichen unterschieden. Groß- und Kleinbuchstaben werden
unterschieden: var und Var sind also zwei
unterschiedliche Namen.
Namen dürfen nicht identisch mit den UniScript Schlüsselwörtern sein. In UniScript sind folgende Wörter reservierte Namen:
break
continue
def
else
except
for
global
if
in
print
return
try
while
Variablennamen dürfen auch nicht mit Funktionsnamen identisch sein:
sin = sin(1) ist nicht zulässig, wohl aber Sin = sin(1).
Gültige Variablennamen sind
_test
var1
Dies_Ist_Ein_Langer_Name
__
a1
Return
während die Namen
1a
Dies ist kein Name
a?3
ungültig sind.
Bei größeren Programmen ist es empfehlenswert, die Namen so zu wählen, daß die Bedeutung und der Typ der Variablen erkennbar sind. Bei den Funktionen, die mit UniScript mitgeliefert werden, bestehen die meisten Namen deshalb aus einem Typpräfix und dem eigentlichen Namen, der mit einem Großbuchstaben anfängt.
Beispiele:
| Name | Bedeutung |
|---|---|
| ssFilename | ss steht für skalarer String. ssFilename wird also einen einzelnen Dateinamen enthalten. |
| svFilename | sv steht für String-Vektor. svFilename wird also vermutlich mehrere Dateinamen enthalten. |
| smSorted | sm steht für String-Matrix. |
| rsXValue | rs steht für reeller Skalar. |
| rvMin | rv steht für reeller Vektor. |
| rmSize | rm steht für reelle Matrix. |
| bVisible | b steht für Bool. Eine solche Variable sollte den Wert wahr oder falsch (TRUE (1) oder FALSE (0)) haben. |
| hLayer | h steht für Zugriffsnummer (handle). |
| hvLayer | hv steht für einen Vektor von Zugriffsnummern. |
| nLayer | n steht für Anzahl und sollte eine ganze Zahl sein, z. B. 123. |
4.11. Vektoren und Matrizen¶
Die folgende Anweisung erzeugt einen Zeilenvektor mit den
Elementen 6, 4 und 13 und weist ihn der Variablen a zu:
a = [6, 4, 13]
Falls die Variable a vorher bereits einen Wert hatte,
wird dieser Wert durch diese Anweisung überschrieben. a ist
nun ein reeller Vektor mit drei Elementen.
Man kann die Variable a in Ausdrücken verwenden. Die
Anweisung:
b = a + 5
addiert den Wert 5 zu allen Elementen von a und weist
das Ergebnis der Variablen b zu. b hat dann den Wert
[11, 9, 18].
Es werden häufig Vektoren der Form [1, 2, 3, 4, 5, ..., n] oder
[1.0, 1.5, 2.0, ...] benötigt. Zur Erzeugung solcher Vektoren steht der
:-Operator zur Verfügung. Es gibt zwei Formen:
start:end
und
start:step:end
Die erste Form entspricht start:1.0:end. step wird zu start
addiert, solange der Wert kleiner oder gleich end ist.
Beispiel:
1:5 ist [1, 2, 3, 4, 5]
1.3:4 ist [1.3, 2.3, 3.3]
1:0.5:2 ist [1, 1.5, 2.0]
start kann größer als end sein
5:1 ist [5, 4, 3, 2, 1]
Ein Vektor ist in UniScript der Spezialfall einer Matrix; [6, 4, 13] ist
eine 1 * 3 Matrix, d.h. sie besteht aus einer Zeile und drei Spalten. Matrizen,
die nur Elemente in einer Zeile enthalten, bezeichnet man auch als Zeilenvektoren.
Spaltenvektoren werden ähnlich eingegeben wie Zeilenvektoren, die Elemente werden jedoch durch ein Semikolon getrennt:
a = [1;2;3]
Spaltenvektoren können mit dem Transponierungsoperator ' in
Zeilenvektoren umgewandelt werden (und umgekehrt).
b = a'
Die Matrix
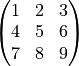
kann man sich als Kombination der Zeilenvektoren [1,2,3], [4,5,6] und
[7,8,9] vorstellen. Sie kann in UniScript folgendermaßen eingegeben werden:
m = [1,2,3; 4,5,6; 7,8,9]
Eine Matrix kann auch aus vorhandenen Vektoren und Matrizen aufgebaut werden, z. B.
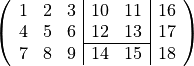
m1 = [1,2,3; 4,5,6; 7,8,9]
m2 = [10,11; 12,13]
v1 = [14,15]
v2 = [16;17;18]
m = [m1, [m2;v1], v2]
4.12. Index-Ausdrücke¶
Auf einzelne Elemente eines Vektors kann über seine Indizes
zugegriffen werden. Hat die Variable a den Wert
[1.5, 3.8, 6.3], dann hat a[1] den Wert 1.5, a[2]
den Wert 3.8 und a[3] den Wert 6.3. Indizes sind ganzzahlige
Werte und beginnen bei 1. Statt eines einzelnen Index kann auch ein
Index-Vektor angegeben werden. So hat a[1, 3] den Wert
[1.5, 6.3] und a[1, 3, 1] den Wert
[1.5, 6.3, 1.5]. Einzelne Indizes können also mehr als
einmal angegeben werden.
Eine Vektor-Variable mit einem Index-Vektor kann auch auf der linken Seite des Zuweisungs-Operators stehen.
a = [1, 2, 3, 4, 5]
a[1, 4] = [-1, 66]
a[1] wird der Wert -1 zugewiesen und a[4] der Wert
66. Der Index-Vektor muss in diesem Fall genauso viele Elemente haben
wie der Vektor auf der rechten Seite des Zuweisungs-Operators. Um zwei
Werte auf Gleichheit zu testen, wird in UniScript der ==-Operator
verwendet. Die Variable a hat nun den Wert [-1, 2, 3, 66, 5].
Die Anweisung
a[1, 4] = a[4, 1]
vertauscht das erste Element mit dem vierten Element des Vektors, ohne die anderen Elemente zu verändern.
Die Anweisung
a[6] = 100
führt zu einem Laufzeitfehler, da der Vektor a nur 5
Elemente hat. Um an den Vektor ein sechstes Element anzuhängen, muss
geschrieben werden
a = [a, 100]
Auf eine Matrix kann mit zwei Indexvektoren die durch ein Semikolon
getrennt sind zugegriffen werden. Der erste Indexvektor ist der
Zeilen-Index-Vektor und der zweite der Spalten-Index-Vektor. Ist die
Matrix a gleich [5,6;7,8] dann ist z. B. a[1;1]
gleich 5 und a[1;2] gleich 6. Entsprechend ist a[1,2;1]
gleich [5,6] die erste Zeile der Matrix a.
Falls ein Zeilen- oder Spalten-Index-Vektor vollständig ist, kann er
auch weggelassen werden. Anstatt a[1,2;1] kann man also schreiben
a[;1], um auf die erste Zeile der Matrix a zuzugreifen.
Eine Matrix wird in UniScript intern als eindimensionaler Vektor spaltenweise gespeichert. Die Elemente der Matrix
werden also in UniScript intern in der Reihenfolge
[1, 4, 7, 2, 5, 8, 3, 6, 9] gespeichert. Auf diese interne Darstellung kann
zugegriffen werden, indem bei Matrizen ein eindimensionaler Indexvektor angegeben
wird. Anstatt a[2;3] (zweite Zeile, dritte Spalte) kann auch a[8]
geschrieben werden. Um auf alle Elemente der Matrix als Vektor zuzugreifen, kann
a[1:9] geschrieben werden, dies entspricht der Schreibweise a[:].
Zusammenfassung
var = start:step:end erzeugt einen Zeilenvektor.
var = start:end erzeugt einen Zeilenvektor mit der Schrittweite 1.0.
var = [e1, e2, e3] erzeugt einen Zeilenvektor.
var = [e1; e2; e3] erzeugt einen Spaltenvektor.
var = [e1, e2; e3, e4] erzeugt eine Matrix.
var[index-vektor] greift auf Elemente eines Vektors zu.
var[zeilen-index-vektor; spalten-index-vektor] greift auf Elemente
einer Matrix zu.
var[zeilen-index-vektor ; ] greift auf die Zeilenvektoren einer
Matrix zu.
var[ ; spalten-index-vektor] greift auf die Spaltenvektoren einer
Matrix zu.
var[:] wandelt eine Matrix in einen Zeilenvektor um.
id-1040188