Import von Daten¶
UniPlot unterstützt die folgenden Datenformate:
Adapt Format, Test Bench Files, MTS Powertrain Technology Division (http://www.mtspt.com)
ASAM-ODS (Browser für API 3 ASAM-ODS Browser (RPC) und API 4 ASAM-ODS Browser (CORBA))
BLF (CAN), siehe Import von CAN-Dateien.
CAS, Combustion Anaylzing System of MTS Powertrain Technology Division and FEV Motorentechnik GmbH, Germany
COMBI, Indiziersystem der Fa. SMETec GmbH
CONVERGE-Datendateien (
*.out,*.in,*.echo). CONVERGE ist der CFD-Löser von Convergent Science (https://convergecfd.com/), siehe Import von CONVERGE Dateien.D7D(
*.rec), Dewesoft (http://www.dewesoft.com/) siehe The D7D Import FilterdBase-Format
DIAdem Daten-Dateien (
*.dat), siehe Importieren von DIAdem-Dateien.DIAdem TDM- bzw. TDMS-Dateien, siehe Import/Export von TDM-Dateien.
Excel (Version 2.1 bis Excel 2016)
ERG(
*.rec), Siemens CATS Flexible, see The ERG Import FilterFAMOS imc Messsysteme GmbH, (http://www.imc-berlin.de), siehe Importieren von FAMOS-Dateien.
FEVIS, Indiziersystem der Fa. enorise GmbH (https://www.enorise.com/). (siehe Import von Fevis-Dateien).
FLEXLAB Browser für API 1 (Discover it <https://www.enorise.com/flex-lab-data-management-test-cell-test-benches _). Siehe :ref:`import-of-flexlab-data.
IFILE, Indiziersystem-Datei der Fa. AVL List GmbH, Graz-Austria, siehe Import von IFILE-Dateien.
MATLAB-Dateien, siehe Import von MATLAB-Dateien.
MDF-Format (MDF-Dateien werden beispielsweise von den Messsystemem VS100/INCA der Fa. ETAS GmbH, Drive-Recorder der Fa. IAV GmbH und CANalyzer der Fa. Vector Informatik GmbH verwendet. Siehe Import von MDF-Dateien)
MDF4, siehe Import von MDF4-Dateien.
MORPHEE Testergebnisdate. (Entdecken Sie es). See Import von MORPHEE Dateien.
netCDF-Dateien
Import von MDF-Stiegele-Dateien (Fa. Stiegele Datensysteme GmbH und Fa. Caesar Datensystem GmbH).
REC DAS700(
*.rec), Sefram (https://www.sefram.com/), siehe Import von REC DAS700.SIMULINK, integrierter Ergebnis-Export über den Sequencer und die MATLAB-App. Siehe Simulink Connector.
Tektronix Waveform Format (
*.isf)Text-Format (ASCII-Dateien bzw. CSV-Dateien)
UTX-Format (UniPlot Text-Dateien), siehe UTX-Datendatei-Format.
Virtual Dynamics Request-Format, see :ref:import-of-virtual-dynamics-req-files.
WFT, Waveform File der Fa. Nicolet
XONE, Test Bench Format, Schenck Pegasus GmbH
UniPlot unterstützt jetzt auch den Import von Kalibrierungsdaten:
DCM file, see Import von Applikationsdaten-Dateien
PACO, see Import von Applikationsdaten-Dateien
Um einen Filter zu installieren, wählen Sie Extras=>Add-In Manager.
Neben diesen vordefinierten Formaten kann UniPlot über die eingebaute Programmierschnittstelle UniScript um weitere firmenspezifische Binär- und Textformate ergänzt werden.
Datensatz-Import¶
Der Datenimport in UniPlot wird in zwei Schritten durchgeführt:
Im ersten Schritt werden die Daten gelesen, konvertiert und als netCDF-Datei gespeichert.
Im zweiten Schritt können die gewünschten Daten aus der netCDF-Datei geladen werden.
Die Konvertierung braucht nur beim Import des ersten Datensatzes durchgeführt werden. Die Zeit, die zur Konvertierung der Text- oder Excel-Dateien erforderlich ist, beträgt je nach Größe der Datei einige Sekunden bis zu mehreren Minuten. Sollen weitere Datensätze geladen werden, kann direkt auf die netCDF-Datei zugegriffen werden.
Die erzeugte netCDF-Datei wird im Verzeichnis der Text- oder Excel-Datei
gespeichert und erhält die Dateinamenserweiterung .nc.
Bei Excel-Dateien wird der Tabellenname an den Dateinamen angehängt.
Um Daten zu laden,
wählen Sie die Funktion Datei=>Daten importieren.
Wählen Sie den gewünschten Dateityp aus.
Wählen Sie die gewünschten Dateien aus.
UniPlot lädt die Daten aus der Datei und erzeugt eine neue Datei mit der Erweiterung
.nc. Wenn eine Datei mit gleichem Namen bereits existiert, wird die Datei überschrieben.Wenn die netCDF-Datei erfolgreich erzeugt werden konnte, wird das folgende Dialogfeld angezeigt:
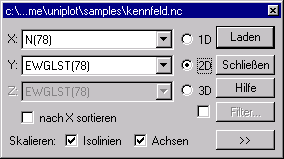
In dieser Maske können Sie die zu importierenden Daten auswählen.
X/Y/Z-Spalte: Um die Daten zu importieren, muss bei den Lesevorschriften die Zuordnung der Spalten der Datendatei zu den Achsen des Diagramms definiert werden. Falls die Spalten Namen haben und die Position der Namen im Dialogfeld Import-Optionen richtig festgelegt wurde, zeigen die Kombinationsfelder diese Namen an. Ansonsten werden die Spalten durchnummeriert (Col1, Col2, …).
Isowerte skalieren: Durch die Wahl des Kontrollkästchens Isowerte skalieren werden beim Import von 3D-Datensätzen aus den Daten der z-Spalte Werte bestimmt, für die Isolinien im Diagramm dargestellt werden. Die Werte werden so ausgewählt, daß die Isolinien möglichst gleichmäßig über das gesamte Kennfeld verteilt sind.
Achsen skalieren: Ist das Kontrollkästchen Achsen skalieren angewählt, wird die x-, y- und die z-Achse automatisch skaliert. Soll die Achseneinteilung des Diagramms nicht neu skaliert werden, darf das Kontrollkästchen nicht markiert sein.
Ausschnitt aus einer ASCII-Messdatendatei:
N MEFF EWGMOM BEEWG ... Leist PME
1/min Nm Nm g/kWh ... kW bar
1249 55.70 53.51 934.1 ... 7.27 7.05
1243 48.97 47.14 933.2 ... 6.14 6.19
... ... ... ... ... ... ...
6730 24.27 23.38 239.1 ... 17.68 3.07
6763 15.66 15.09 157.7 ... 11.71 1.98
6740 8.04 7.75 123.6 ... 5.99 1.02
Der Import-Filter für ASCII-Dateien findet das Spaltentrennzeichen, das Dezimaltrennzeichen, die Kanalnamen und Kanaleinheiten selbständig.
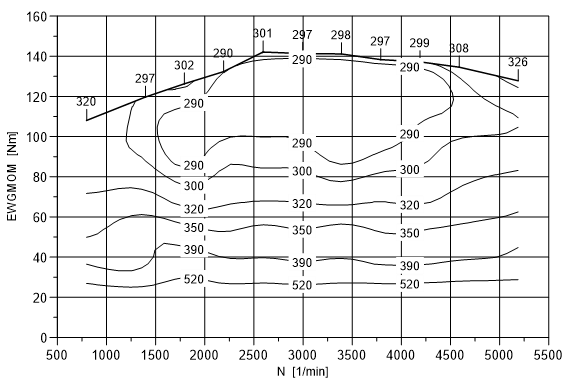
Beispiel: Für den Ausschnitt der Datei soll ein
Kraftstoffverbrauchskennfeld in Abhängigkeit von Drehzahl und Moment
dargestellt werden. Dazu muss der x-Achse die Spalte N, der y-
Achse die Spalte MEFF und der z-Achse die Werte der Spalte
BEEWG zugeordnet werden. In der letzten Spalte können
Kennbuchstaben eingegeben werden, die die Darstellung der Volllastlinie
festlegen. Damit die Daten als 3D-Datensatz geladen werden, muss die
Optionsschaltfläche 3D ausgewählt sein. Haben Sie alle Einstellungen
vorgenommen, wählen Sie die Schaltfläche Laden, um von den
Daten einen Isolinien-Datensatz zu erzeugen.
Formatvorschriften für CSV-, Text- und Excel-Dateien¶
Für CSV- (Comma-Separated Values) Text- und Excel-Dateien müssen folgende Formatierungsvorschriften beachtet werden:
Die Daten müssen in Spalten angeordnet sein. Die erste Datenzeile muss innerhalb der ersten 256 Zeilen stehen.
Spaltenanzahl: Die maximale Spaltenanzahl ist auf 8000 begrenzt.
Zeilenanzahl: Die maximale Zeilenanzahl wird nur durch den verfügbaren Speicher begrenzt. Für einen 1D- oder 2D-Datensatz ist mindestens 1 Datenzeile erforderlich, für einen 3D-Datensatz mindestens 5 Datenzeilen.
Spaltentrennzeichen: Mögliche Spaltentrennzeichen bei Text-Dateien sind:
Spaltentrennzeichen |
Beschreibung |
|---|---|
|
Semikolon |
|
Tabulatorzeichen |
|
Komma |
|
Ein oder mehrere Leerzeichen |
Das Spaltentrennzeichen sucht der Filter nach folgender Regel: Das Zeichen wird als Trennzeichen verwendet, welches am häufigsten in den letzten 4 Zeilen der ersten 256 Zeilen auftritt. Falls das Trennzeichen ein Komma ist, muss als Dezimaltrennzeichen ein Punkt verwendet worden sein. Das Leerzeichen wird nur dann als Spaltentrennzeichen verwendet, falls kein anderes Trennzeichen gefunden wurde.
Dezimaltrennzeichen: Gültige Dezimaltrennzeichen sind der Punkt (.) oder ein Komma (,). Das Dezimaltrennzeichen wird automatisch erkannt.
Spaltentyp: Die Spalten werden als real4 (float) gespeichert. Falls eine Spalte keine gültigen Zahlenwerte enthält, wird die Spalte als Text-Spalte gespeichert. Falls die Textelemente als gültiges Datum formatiert sind, z. B. 17.01.2007, werden die Spalten als Zeit- bzw. Datum-Spalte gespeichert.
Missing Values: Falls eine Spalte neben gültigen Zahlenwerten nur noch
leere Zellen oder nur die Zeichen "*", "-", "#" (ein oder mehrere) enthält,
werden diese Zellen als missing markiert. Zellen, die die folgenden
Werte enthalten, werden ebenfalls als ungültige Zahlen gespeichert, wobei
Groß-/Kleinschreibung ignoriert wird: „not a number“, „nan“, „1.#inf“,
„no value“, „missing*“. Mit dem Zeichen "#" in der ersten Spalte kann eine
Zeile in der Datei auskommentiert werden. Die Zahlenwerte der Zeile
werden in der NC-Datei dann als missing_value gespeichert.
Kanalnamen und Einheit: Über den eigentlichen Daten können noch Kanalnamen und Einheiten stehen, wobei die Kanalnamen über den Einheiten stehen müssen. Die Kanalnamen sollten alle unterschiedlich sein. Nur wenn 80 % aller Namen voneinander verschieden sind, werden Sie als Kanalnamen erkannt. Die Kanalnamen können zur Benennung der Diagramm-Achsen und der Datensätze verwendet werden. Falls keine Kanalnamen gefunden werden, erhalten die Spalten die Namen Col1 bis Coln. Falls gleiche Namen auftreten, werden die Namen durchnummeriert, da in der NC-Datei nur eindeutige Namen erlaubt sind.
Kommentarzeilen: Über den Datenspalten können Kommentarzeilen stehen, die überlesen werden.
Anführungsstriche („“): An Anführungsstriche werden entfernt. Trennzeichen innerhalb von Anführungsstriche werden ignoriert. Zahlenwerte in Anführungsstrichen werden als Text behandelt.
Das folgende Beispiel zeigt eine gültige Datei im Text-Format. In der ersten Spalte enthält die Datei die Drehzahlwerte, in der zweiten das Moment und in der dritten Spalte die Leistung.
Drehz Mom Lst
1/min Nm kW
1249 55.70 53.51
1243 48.97 47.14
3567 38.54 27.14
6763 15.66 15.09
6740 8.04 7.75
Alle Datenzeilen sollten die gleiche Anzahl an Spalten haben. Im folgenden Ausschnitt einer Textdatei enthält die fünfte Zeile nur drei Zahlenwerte. Der dritte Wert des Kanal Lst wird in der NC-Datei als „missing“ gespeichert.
Drehz; Mom; Lst; B
1/min; Nm; kW; -
1249; 55.70; 53.51; 7.27
1243; 48.97; 47.14; 6.14
6730; 24.27; ; 239.1
6763; 15.66; 12.03; 15.09
6740; 8.04 ; 7.75; 5.99
Gültige Text-Datei mit Datum- und Zeitspalte. Textelemente dürfen in Anführungszeichen stehen. Die Anführungszeichen werden entfernt. Bei den Kanalnamen, die ein Leerzeichen enthalten, wird das Leerzeichen durch einen Unterstrich ersetzt.
"Date","Time","Rate","Num Average","Operator ID","State Label","Sample Label","Engine_upl"
,,V,,,,,""
"27/04/2006","09:59:13.150",1.000000000000000000,1.0,,,,"Otto",
"27/04/2006","09:59:13.250",2.000000000000000000,1.1,,,,"Otto",
"27/04/2006","09:59:13.350",3.000000000000000000,1.2,,,,"Otto",
"27/04/2006","09:59:13.450",4.000000000000000000,1.3,,,,"Otto",
UTX-Datendatei-Format¶
Im Folgenden wird ein einfach zu erzeugendes und gut lesbares Datendatei-Format für UniPlot beschrieben (UTX-Format).
Vorteile
Leicht mit allen Programmiersprachen zu erzeugen.
Die Datendatei kann mit einem Texteditor oder einem Tabellenkalkulationsprogramm per Hand erzeugt oder geändert werden.
Vorhandene spaltenweise angeordnete Datendateien können einfach in dieses Format umgewandelt werden.
Nachteile
Alle Kanäle (Spalten) der Datei müssen die gleiche Anzahl an Messpunkten haben.
Aufbau des Formats¶
Die Datei besteht aus zwei Blöcken, dem Beschreibungsblock und dem Datenblock.
Die Datei beginnt mit dem Block, der die beschreibenden Daten
enthält. Der Block beginnt mit dem Schlüsselwort UXX-BEGIN
(Groß-/Kleinschreibung wird ignoriert) und endet mit dem Schlüsselwort
UXX-END.
Dem Beschreibungsblock folgt der Datenblock. Der Datenblock besteht entweder aus spaltenweise angeordneten Daten im Text-Format (ASCII-Format).
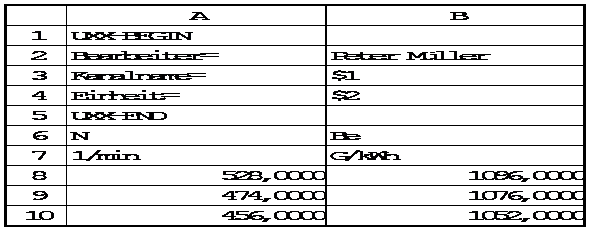
Beispiel 1 Die folgende Beispieldatei enthält zwei Kanäle: den Kanal N (Drehzahl) in der ersten Spalte und den Kanal Be (spez. Kraftstoffverbrauch) in der zweiten Spalte. Die beiden Spalten sind durch ein Trennzeichen getrennt.
Im Kopf der Datei sind 3 Attribute angegeben: Bearbeiter, Kanalname und Einheit.
Kanalname und Einheit sind dabei sogenannte Kanalattribute, d. h. für jeden Kanal
in der Datei ist ein Wert vorhanden. $1 bei Kanalname bedeutet, daß sich die
Werte des Attributs eine Zeile hinter dem Kopf befinden. Kanalname hat also die
beiden Werte N und Be. Entsprechend hat das Attribut Einheit die beiden Werte
1/min und g/kWh. Das Attribut "Bearbeiter" ist ein globales Attribut mit
dem Wert "Peter Müller". Es bezieht sich auf die ganze Datei.
UXX-BEGIN
Spaltentrennzeichen= " "
Bearbeiter= Peter Müller
Kanalname= $1
Einheit= $2
UXX-END
N Be
1/min g/kWh
528,000 1096,00
474,300 1076,00
456,000 1052,00
Beispiel 2 UniPlot kann die Dateien auch dann lesen, wenn sie mit dem Tabellenkalkulationsprogramm Excel erstellt worden sind (alle Formate inklusive Excel 2007). In diesem Fall sollte das Wort UXX-BEGIN in der Zelle A1, die Attributnamen in der ersten Spalte und die Attributwerte in der zweiten Spalte stehen.
Beispiel 3 Die Daten sind in Zeilen anstatt in Spalten angeordnet. In diesem
Fall muss die Datei das Attribut uxx-transposed = 1 enthalten.
UXX-BEGIN
Spaltentrennzeichen= " "
Bearbeiter= Peter Müller
Kanalname= $1
Einheit= $2
uxx-transposed = 1
UXX-END
N 1/min 528,000 474,300 456,000
Be g/kWh 1096,00 1076,00 1052,00
Der Beschreibungsblock¶
Der Beschreibungsblock besteht aus globalen Attributen (die sich auf die gesamte Datei beziehen) und Kanal-Attributen.
Globale Attribute haben die Form von Anweisungen:
NAME = WERT
oder
NAME = WERTELISTE
Dabei kann NAME eine bis zu 40 Zeichen lange Zeichenkette sein,
die mit einem Unterstrich "_" oder einem Buchstaben beginnt,
dem bis zu 39 Buchstaben, Unterstriche und Ziffern folgen können.
Sonderzeichen und Umlaute sind in NAME nicht erlaubt. Die
Zeichenfolgen UXX-BEGIN und UXX-END sind als Namen nicht erlaubt. WERT
kann entweder eine ganze Zahl (Integer), eine Gleitkommazahl (Real)
oder eine Zeichenkette (String) sein.
Integer
Eine ganze Zahl hat die Form 123 oder -123. Falls in der Zahl ein Dezimaltrennzeichen vorhanden ist, wird die Zahl als Real-Zahl gespeichert. Z. B. wird 1.23e2 (= 123) als Real-Zahl gespeichert.
Real
Eine Gleitkommazahl (Real-Zahl) hat die Form 12.3e1, 123. oder 123.0. Als Dezimaltrennzeichen kann ein Punkt oder ein Komma verwendet werden. Falls die Dateien im deutschsprachigen Raum mit dem Tabellenkalkulationsprogramm Excel bearbeitet werden sollen, empfiehlt sich die Verwendung des Kommas als Dezimaltrennzeichen.
String
Falls der Attributwert weder eine Integerzahl noch eine Real- Zahl ist, wird der Attributwert als String gespeichert. Als Zeichensatz sollte der Windows ANSI-Zeichensatz verwendet werden (siehe Tabelle im Anhang).
Datum= 12.06.1998
Motor= 12AT29
Zeichenketten können in Anführungszeichen eingeschlossen werden.
WERTELISTE ist eine Folge von Werten eines Datentyps (entweder Integer, Real oder String), die durch Trennzeichen (standardmäßig das Tabulatorzeichen) getrennt sind.
Parameter= 12 24 22,5
Range= 1 24576
Kanalattribute
Die Attribute für die Kanäle haben die Form einer in eckigen Klammern eingeschlossenen Liste von Werten, wobei die Werte durch Trennzeichen (standardmäßig das Tabulatorzeichen) getrennt werden.
NAME = [WERT WERT WERT]
Dabei muss für jeden Kanal ein WERT vorhanden sein. Die Reihenfolge der Werte entspricht der Reihenfolge der Kanäle im Datenblock. Alle Werte müssen vom gleichen Typ sein, d.h. Zahlen und Zeichenketten dürfen für ein Attribut nicht gemixt werden.
Anstatt die Attribute für die Kanäle in der Form
NAME = [ WERTELISTE ]
zu schreiben, können die Kanalattribute alternativ in der Form
NAME = $ZEILENNUMMER
geschrieben werden. Das bedeutet, das sich die Attributwerte des Attributs NAME in der Zeile ZEILENNUMMER hinter dem UXX-END des Beschreibungsblocks befinden. Die Dateien können dann einfacher mit Tabellenkalkulationsprogrammen bearbeitet werden. Falls der Datenblock binär ist, müssen die Kanalattribute in der ersten Form geschrieben werden.
Fortsetzungszeilen¶
Attribute können über mehrere Zeilen geschrieben werden. Dazu wird mit
dem kaufmännischen Und-Zeichen "&" eine Fortsetzungszeile
eingeleitet. Das Und-Zeichen darf nur hinter dem Gleichheitszeichen
oder dem Spaltentrennzeichen stehen.
Beispiel:
Kanalname = [N &
Mom &
Leist]
Entspricht
Kanalname = [N Mom Leist]
Fortsetzungszeilen sind nur im Beschreibungsblock und nicht im Datenblock zulässig.
Kommentare¶
Der Beschreibungsblock kann Kommentare enthalten. Kommentare
werden durch das Zeichen "#" eingeleitet. Dabei muß das
Kommentarzeichen das erste Zeichen der Zeile sein.
Ab UniPlot 5.12.0 können auch Datenzeilen mit dem Zeichen
"#" auskommentiert werden. Die Zahlenwerte der Zeile
werden in der NC-Datei dann als missing_value gespeichert.
Der Datenblock¶
Der Datenblock wird als Textblock formatiert und kann mit einem Texteditor bearbeitet werden.
Der Text-Datenblock¶
Der Datenblock kann beliebig viele Zeilen (Datenpunkte) haben. Eine Zeile kann beliebig lang sein.
Die Spalten sind standardmässig durch Tabulatorzeichen getrennt.
Falls ein anderes Trennzeichen verwendet werden soll, muss im
Beschreibungsblock das globale Attribut Spaltentrennzeichen vorhanden
sein, z. B.: Spaltentrennzeichen = ";"
Fortsetzungszeilen und Kommentare sind im Datenblock nicht erlaubt. Leerzeilen werden ignoriert.
Kanäle mit Datum/Zeit können in der Form "25.01.1996 8:30:00",
"25.01.1996" (nur Datum) oder
"8:30:00" (nur Zeit) eingegeben werden.
Die Standard-Attribute¶
Die folgenden Attribute sind für UniPlot reserviert, das heißt diese Attribute haben in UniPlot eine definierte Bedeutung:
globale Attribute
Deutsch |
Englisch |
|---|---|
Spaltentrennzeichen |
Columnseparator |
Schema |
Scheme |
uxx-transposed |
uxx-transposed |
Kanalattribute
Deutsch |
Englisch |
|---|---|
Kanalname |
Channelname |
Einheit |
Unit |
Datentyp |
Datatype |
Bei den Standardattributen wird nicht zwischen Groß-/Kleinschreibung und Deutsch/Englisch unterschieden (Datentyp, datentyp, datatype beschreiben das selbe Attribut).
uxx-transposed¶
Falls die Daten in Zeilen anstatt in Spalten angeordnet sind, kann man
dies dem Import-Filter über das Attribut uxx-transposed = 1
mitteilen. Falls die Daten in Spalten angeordnet sind, muss das Attribut
nicht angegeben werden (Default = 0).
UXX-BEGIN
Spaltentrennzeichen= " "
Bearbeiter= Peter Müller
Kanalname= $1
Einheit= $2
uxx-transposed = 1
UXX-END
N 1/min 528,000 474,300 456,000
Be g/kWh 1096,00 1076,00 1052,00
Kanalname (channelname)¶
Dieses Attribut muss vorhanden sein.
Die Namen sollten nach den gleichen Regeln wie der Attributname aufgebaut sein, d.h. mit einem Unterstrich oder einem Buchstaben beginnen, dem bis zu 39 Unterstriche, Buchstaben oder Ziffern folgen. In den Namen sollten keine Leerzeichen und Umlaute oder Sonderzeichen vorhanden sein.
Kanalname= [N Mom beewg]
Anstatt die Attribute für die Kanäle in der Form
Kanalname = [ WERTELISTE ]
zu schreiben, können die Kanalattribute alternativ in der Form
Kanalname = $ZEILENNUMMER
geschrieben werden. Das bedeutet, das sich die Kanalnamen in der Zeile ZEILENNUMMER hinter dem UXX-END des Beschreibungsblocks befinden. Die Dateien können dann einfacher mit Tabellenkalkulationsprogrammen bearbeitet werden. Falls der Datenblock binär ist, müssen die Kanalattribute in der ersten Form geschrieben werden.
Falls die Kanalname in der Form Name [unit]
definiert sind und ansonsten keine Einheiten vorhanden sind, wird der Kanalname
in Name und Einheit zerlegt. Aus dem N [1/min] wird der
Kanalnamen N und die Einheit 1/min erzeugt.
Das Zerlegen der Kanalnamen in Name und Einheit kann mit dem folgenden Aufruf im Kommandofenster abgeschaltet werden.
WriteProfileInt("Settings", "UTX_Split_Name_Unit", 0)
Spaltentrennzeichen (columnseparator)¶
Falls das Attribut Spaltentrennzeichen nicht angegeben wird, müssen die Spalten durch ein Tabulatorzeichen getrennt sein. Mögliche Trennzeichen sind:
Zeichen |
Bedeutung |
|---|---|
|
(Defaultwert) Ein einzelnes Tabulatorzeichen (backslash + t). |
|
Mehrere zusammenhängende Leer- und Tabulatorzeichen. |
|
Ein einzelnes Leerzeichen (backslash + b). |
|
Ein Semikolon. |
|
Ein Komma. |
|
Ein einzelnes, beliebiges Zeichen. |
Spaltentrennzeichen= ";"
Falls als Spaltentrennzeichen „ „ verwendet wird, sollten alle Spalten vollständig sein. Aufeinander folgende Leer- und Tabulatorzeichen werden bei diesem Trennzeichen wie ein Trennzeichen behandelt. Falls also ein Wert in der Spalte fehlen würde, würde der Wert des nächsten Kanals eingetragen.
Einheit (unit)¶
Einheit des Kanals.
Einheit= [1/min Nm g/kWh]
Datentyp (datatype)¶
Datentyp beschreibt den Datentyp des Kanals. Das Attribut legt
fest, wie die Werte konvertiert werden. Falls das Attribut nicht
vorhanden ist, werden die Kanäle als "real4" (float)
gespeichert. Bei dem Attribut Datentyp sind folgende Werte zulässig:
Datentyp |
Bedeutung |
|---|---|
int1 |
Ein-Byte-Integer mit Vorzeichen |
uint1 |
Ein-Byte-Integer ohne Vorzeichen |
int2 |
Zwei-Byte-Integer mit Vorzeichen |
uint2 |
Zwei-Byte-Integer ohne Vorzeichen |
int4 |
Vier-Byte-Integer mit Vorzeichen |
uint4 |
Vier-Byte-Integer ohne Vorzeichen |
real4 |
Gleitkommazahl (4 Bytes). |
real8 |
Doppelt genaue Gleitkommazahl (8 Bytes). |
stringNNN |
Zeichenkette mit Längenangabe. NNN steht für eine ganze Zahl im Bereich 1 bis 255, z. B. string80. |
date |
Datum (8 Bytes) |
time |
Zeit (8 Bytes) |
datetime |
Datum und Zeit (8 Bytes) |
Datentyp= [date real4 string12]
Die Liste muss nicht vollständig sein. Falls beispielsweise der zweite
Kanal ein Zeitkanal ist, müssen nur die ersten beiden Datentypen
angegeben werden. Alle nachfolgenden Kanäle werden als "real"
gespeichert.
Schema (scheme)¶
Schema ist eine Zeichenkette, die sich aus dem Firmennamen und/oder Programmnamen des erzeugenden Programms zusammensetzt. Zusätzlich sollte noch eine Versionsnummer angehängt werden. Falls das Programm so geändert wird, das zusätzliche Attribute geschrieben werden, oder sich die Bedeutung der Attribute ändert, sollte die Versionsnummer hochgezählt werden.
Beispiel: (Firmenname AVM, Prüfstandsprogramm P13, Version 1)
Schema= AVM P13-1
Kurzbeschreibung zur Erzeugung des Datenformats¶
Um Ihre Daten im UTX-Format zu speichern, gehen Sie folgendermaßen vor:
Erzeugen Sie eine Datei mit der Dateinamenerweiterung
.utxoder alternativ.txt.Schreiben Sie die Zeile UXX-BEGIN gefolgt von den beiden Zeilentrennzeichen 0x0d und 0x0a (neue Zeile).
(Optional) Schreiben Sie eine oder mehrere Kommentarzeilen aus denen hervorgeht, welches Programm die Datei erzeugt hat.
Schreiben Sie das globale Attribut Schema, z. B.:
Schema= "AKT-W15"
Schreiben Sie Ihre eigenen globalen Attribute, z. B.:
Bearbeiter= "Herr Müller" Bohrung= 86,0 Luftdruck= "1013 mbar" MinMax= 0 236,0
Schreiben Sie die Kanalattribute
"Kanalname","Einheit"und"Datentyp":Kanalname= $1 Einheit= $2 Datentyp= $3
Schreiben Sie Ihre eigenen Kanalattribute.
Schreiben Sie die Zeichenkette UXX-END gefolgt von den beiden Zeilentrennzeichen 0x0d und 0x0a.
Schreiben Sie die Werte der Kanalattribute (jeweils durch ein Tabulatorzeichen getrennt).
N Mom Beewg 1/min Nm g/kWh real8 real8 real8
Schreiben Sie die Daten der Kanäle (jeweils durch ein Tabulatorzeichen getrennt). Verwenden Sie als Dezimaltrennzeichen entweder das Komma oder den Punkt.
1000,2 32,23 267,6 1501,8 42,45 284,5 2004,2 48,44 296,3
Import von eigenen Text-Dateien mit Hilfe des UTX-Filters.¶
Der einfache Text-Import-Filter erwartet, dass die Datenmatrix
vollständig ist. Es dürfen also keine Messwerte fehlen. Vielfach
kommt es jedoch vor, dass Messpunkte ungültig sind. Die Punkte
werden dann beispielsweise durch ** markiert.
Mit Hilfe des UTX-Filters können für solche Text-Dateien relativ einfach eigene Filter mit Hilfe von UniScript geschrieben werden. Es folgt für die folgende einfache Text-Datei ein Beispiel:
N Mom Beewg NOx
1/min Nm g/kWh ppm
1000,2 32,23 267,6 990
1501,8 42,45 ** 1100
2004,2 48,44 296,3 1200
ADDIN_AddToUI(ADDIN_FILE_IMPORT, "Prüfstands-Dateien (*.ascii)|*.ascii|", "_My_Import");
// Prüft ob Dateiname mit .ascii endet
def IsFileMyImport_ASCII(ssFileName)
{
if (strlower(SplitPath(ssFileName)[4]) == ".ascii") {
return TRUE;
}
return FALSE;
}
// Liefert den Header für den UTX-Filter
def _My_GetHeader()
{
ssHeader = "[[UXX-BEGIN
Creator= Prüfstands-ASCII-FILTER
Kanalname= $1
Einheit= $2
UXX-END
]]";
return ssHeader;
}
def _My_Import(ssFileName)
{
if (IsFileMyImport_ASCII(ssFileName) == FALSE) {
// Dateiname endet nicht mit .ascii
return "";
}
if (IsFunctionLoaded("UXX_Import") == FALSE) {
MessageBoxError("Datei kann nicht importiert werden, da der UTX-Filter nicht geladen ist.\n" + ..
"Wählen Sie Extras=Addin-Manager und markieren Sie das Addin UTX-Filter.");
return "#IMPORTERROR#";
}
// Schreibt den Header in eine Temp-Datei,
// die am Ende der Funktion wieder gelöscht wird.
ssHeader = _My_GetHeader();
ssTempFile = GetTempFileName();
fp = fopen(ssTempFile, "wt");
if (fp == 0) {
return "#IMPORTERROR#";
}
fwrite(fp, "char", ssHeader);
fclose(fp);
// Aufruf des UTX-Filters:
ssRet = UXX_Import([ssFileName, ssTempFile]);
// Temp-Datei löschen:
DeleteFile(ssTempFile);
return ssRet;
}
Das Beispiel verwendet den UTX-Filter, um die Messdaten zu importieren. Der UTX-Filter wird mit dem Funktion-Aufruf UXX_Import() gestartet. Der Funktion werden zwei Dateinamen als Vektor übergeben. Der erste Name ist der Dateiname der Messdaten-Datei. Der zweite Dateiname mit den Kopfdaten, wie sie vom UTX-Filter erwartet werden.
In diesem Fall wird der Kopf in eine temporäre Datei geschrieben, die am Ende der Funktion wieder gelöscht wird. Der Kopf wird in der Funktion _My_GetHeader() definiert. Man könnte den Kopf auch direkt in eine Datei schreiben, und den Dateinamen an die Funktion UXX_Import() übergeben.
Im Kopf wird festgelegt, wo sich die Kanalnamen und Einheiten in der Messdatei stehen.
Der Programmtext kann in einer IC-Datei im autolaod-Verzeichnis von
UniPlot gespeichert werden. Der Dateiname muss mit .ic enden, beispielsweise
my_import.ic. Beim Start von UniPlot werden alle IC-Dateien aus
dem autolaod-Verzeichnis automatisch geladen.
Import von 3D-Matrix-Daten¶
Um eine Datenmatrix aus einer Text- oder Excel-Datei zu laden, gehen Sie wie folgt vor:
Wählen Sie die Funktion Datei=>Weitere Datei-Funktionen.
Wählen Sie aus dem Listenfeld die Funktion Matrix laden.
Wählen Sie die Datei mit der Datenmatrix im Datei-Öffnen-Dialog.
Wurde eine gültige Datei mit einer Zahlenmatrix geladen, wird ein Dialogfeld angezeigt, in dem die Koordinaten der Eckpunkte der Matrix in der x/y-Ebene eingegeben werden müssen.
Die Spalten- und Zeilenanzahl der Matrix muss zwischen 5 und 100 liegen. Die Matrix muss nicht quadratisch sein. Weitere Informationen über das Matrix-Format entnehmen Sie bitte der UniPlot-Referenz (siehe Datei=>Weitere Datei-Funktionen=>3D Daten-Matrix laden).
Definition der Volllastlinie¶
Automatische Ermittlung der nicht-konvexen Hülle¶
Falls die Messdaten in Form von Kennfeldschnitten vorliegen, z. B. in Form von Drehzahlschnitten, kann die nicht-konvexe Hülle automatisch ermittelt werden. Die Messdaten müssen dazu bei etwa konstanten x-Koordinaten gemessen worden sein. Für die Abweichung der x-Koordinaten von einem exakten Wert wird eine Toleranz vorgegeben. Das Programm sucht für jeden Schnitt den Wert mit der minimalen bzw. maximalen y-Koordinate. Aus den minimalen y-Koordinaten wird die Schleppkurve, aus den maximalen y-Koordinaten wird die Volllastlinie gebildet.
Um die Funktion auszuführen, markieren Sie ein Kennfeld und wählen Sie die Funktion Daten=>Weitere Daten-Funktionen (3D). Aus der folgenden Liste wählen Sie die Funktion Hüllkurve bestimmen.
Im folgenden Dialogfeld können Sie festlegen, wie die Hüllkurve beschriftet werden soll. Es besteht die Auswahl zwischen der Beschriftung jedes Datenpunkts der Hülle oder jedes zweiten Punktes. Sie können die Beschriftung auch abschalten.
Die x-Klassenbreite legt den Toleranzbereich fest, in dem die x-Koordinaten eines Kennfeldschnittes liegen sollen.
Die Hülle wird als Benutzerhülle im Datensatz gespeichert.
UniPlot berechnet beim Laden von 3D-Daten automatisch eine konvexe Hülle. Die Volllastkurve ist dabei der „nördlichste“ Teil der konvexen Hülle. Im allgemeinen ist die Volllastkurve jedoch nicht konvex.
Soll die wahre Volllastkurve dargestellt werden, muss die Datei, aus der die Daten importiert werden, mit einem Editor oder einem Tabellenkalkulationsprogramm bearbeitet werden. Dazu wird in der letzten Spalte ein Kennbuchstabe zur Markierung der Datenpunkte eingegeben. Für die Markierung der Volllastkurve stehen die folgenden Kennbuchstaben zur Verfügung:
- A
Erster Punkt der Volllastkurve. Der Punkt muss zur automatisch berechneten Volllastkurve („nördlichster“ Teil der konvexen Hülle) gehören und eine kleinere x-Koordinate als der Endpunkt E haben.
- V
Volllast-Punkt.
- E
Letzter Punkt der Volllastkurve. Der Punkt muss zur automatisch berechneten Volllastkurve („nördlichster“ Teil der konvexen Hülle) gehören und eine größere x-Koordinate als der Anfangspunkt A haben.
Wird der Kennbuchstabe als Kleinbuchstabe (a, v, e) eingegeben, wird der entsprechende Datenpunkt der Volllastkurve nicht beschriftet. Dadurch kann vermieden werden, daß sich Beschriftungen, die zu dicht beieinander liegen, überdecken.
Vorgehensweise
Für die Erstellung der Volllastlinie empfiehlt sich folgende Vorgehensweise:
Laden Sie aus der Datei einen Kennfelddatensatz.
Lassen Sie von UniPlot die Volllastlinie als Polygonzug darstellen. Wählen Sie dazu im Menü Daten den Befehl 2 1/2D-Isolinien. Wählen Sie die Seite Isolinien und wählen Sie für die Verbindung der Isolinienpunkte die Optionsschaltfläche Polygon. Wählen Sie danach die Seite Marken und schalten Sie die Streu-Diagramm-Darstellung ein.
Laden Sie die Datei mit den Kennfelddaten in ein Programm, mit dem Sie die Daten editieren können. Falls die Daten im ASCII-Format vorliegen, können Sie dazu den Editor von UniPlot verwenden.
Wechseln Sie in das Programm UniPlot.
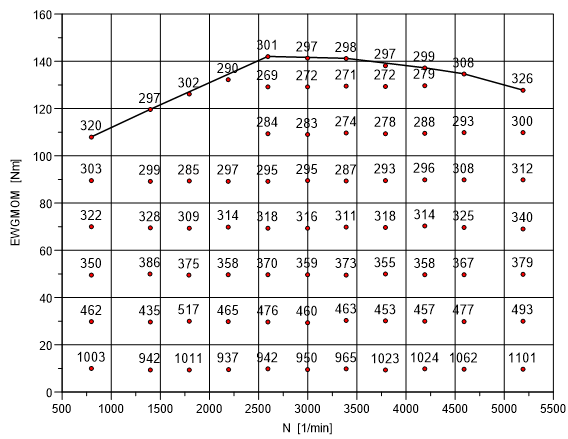
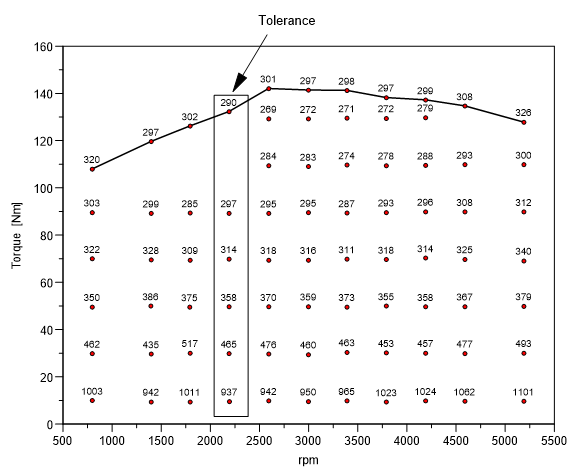
Sie erkennen in obiger Abbildung, daß die Punkte mit den z-Werten 320, 297, 301, 298, 299, 308, 326 zur vom Programm ermittelten Volllastlinie gehören.
Sie können anhand des Streudiagramms und der von UniPlot bestimmten Volllastlinie sehr leicht die wahre Volllastlinie bestimmen. Markieren Sie dazu wie oben beschrieben den Anfangspunkt und den Endpunkt sowie alle weiteren zur Volllastlinie gehörenden Messpunkte, falls sie nicht schon zur von UniPlot berechneten Volllastkurve gehören. In der folgenden Abbildung wurde die Zeile mit dem z-Wert 320 mit einem A markiert und die Zeilen mit den z-Werten 297, 302, 290, 301, 297, 298, 297, 299, 308 mit einem V. Die Zeile mit dem z-Wert 326 wurde mit einem E markiert.
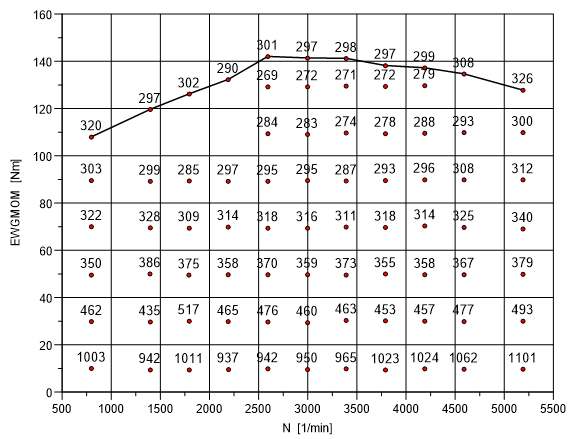
Speichern Sie die Änderungen und schließen die Datei. Um nun den Datensatz mit der korrigierten Volllastlinie zu erzeugen, müssen die Daten erneut importiert werden. Sie erhalten die obige Abbildung.
Freie Definition einer Datenhülle¶
UniPlot ermöglicht das Einlesen einer beliebig geformten Datenhülle, die auch Inseln enthalten kann.
Die Hülle wird für die graphische Ausgabe des Isolinien-Diagramms und der 3D-Oberfläche verwendet. Beim Isolinien-Diagramm werden die Isolinien nur innerhalb der Datenhülle ausgegeben. Bei der 3D-Darstellung werden nur die Facetten der Oberfläche ausgegeben, die vollständig innerhalb der Hülle liegen.
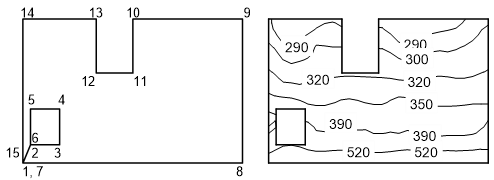
Die Datenhülle muss als dreispaltige Text- oder Excel-Datei vorliegen. Die erste und zweite Spalte enthält die x- und y-Koordinaten der Hüllenpunkte und die dritte Spalte enthält einen Kennbuchstaben. Der Kennbuchstabe legt fest, welche Punkte durch Linien verbunden werden sollen.
Als Kennbuchstaben sind die folgenden vier Zeichen zulässig:
m ist die Abkürzung für MoveTo. Der Kennbuchstabe bewirkt, daß zu diesem Punkt eine nicht sichtbare Linie gezogen wird. Der Kennbuchstabe kann verwendet werden, um Inseln zu erreichen, ohne das die Verbindungslinie ausgegeben wird.
M hat die gleiche Bedeutung wie m, jedoch wird der Punkt durch den z-Wert des Kennfeldes an dieser Stelle beschriftet.
l ist die Abkürzung für LineTo. Der Kennbuchstabe bewirkt, daß zu diesem Punkt eine sichtbare Linie gezogen wird.
L hat die gleiche Bedeutung wie l, jedoch wird der Punkt durch den z-Wert des Kennfeldes an dieser Stelle beschriftet.
Beispiel:
Unten sehen Sie die ASCII-Datei der dargestellten Hülle. Die Zahlen in Klammern beziehen sich auf die Nummerierung in der Abbildung. Sie dürfen nicht in die Hüllendatei eingegeben werden.
1500 20 m (1)
1600 30 m (2)
2000 30 l (3)
2000 50 l (4)
1600 50 l (5)
1600 30 l (6)
1500 20 m (7)
4500 20 l (8)
4500 100 l (9)
3000 100 l (10)
3000 70 l (11)
2500 70 l (12)
2500 100 l (13)
1500 100 l (14)
1500 20 l (15)
Speichern einer Hülle¶
Um die Hülle eines 3D-Datensatzes zu speichern, markieren Sie den Datensatz und wählen Sie die Funktion Datei=>Weitere Datei-Funktionen, Eintrag Hülle speichern.
Laden der Hülle¶
Um eine Hülle in einen 3D-Datensatz zu laden, markieren Sie den Datensatz und wählen anschließend die Funktion Datei=>Weitere Datei-Funktionen. Aus der folgenden Liste wählen Sie den Eintrag Hülle laden.
Daten-Import in ein Wasserfalldiagramm¶
Für den Import von Daten in ein Wasserfalldiagramm stehen zwei Funktionen zur Auswahl. Die Daten können aus einem Kanal importiert werden, der mehrere Perioden enthält oder es können mehrere Kanäle aus einer Datei geladen werden.
Periodische Daten importieren¶
Um Einzelzyklen aus einem periodischen Signal zu importieren, gehen Sie wie folgt vor:
Wählen Sie die Funktion Datei=>Weitere Datei-Funktionen.
Wählen Sie aus dem Listenfeld die Funktion Wasserfall-Einzel-Zyklen-Import.
Wählen Sie die Datei mit der Datenmatrix im Datei-Öffnen-Dialog.
Wurde eine gültige Datei mit einer Zahlenmatrix geladen, wird ein Dialogfeld mit den Kanalnamen, die in der Datei gefunden wurden, angezeigt:
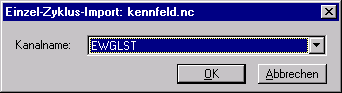
Wählen Sie einen Kanal aus und klicken Sie dann auf die OK-Schaltfläche.
Im folgenden Dialog können Sie festlegen, welche Zyklen aus der Datei geladen werden sollen:
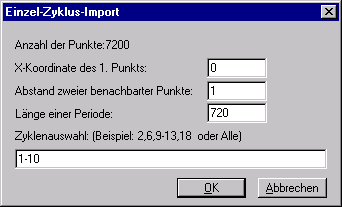
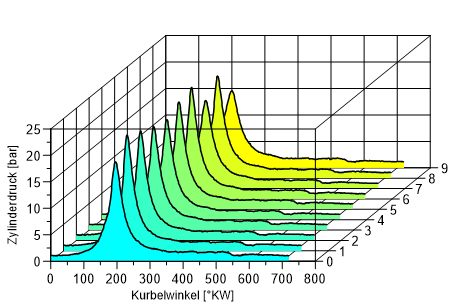
In diesem Beispiel werden die Zyklen 1 bis 10 geladen. Die Zykluslänge beträgt 720 Grad KW. Der erste Punkt in der Datei hat den Kurbelwinkel 0 Grad KW. Die Daten wurden mit einer Kurbelwinkelteilung von 1 Grad KW gemessen. Wenn Sie die Daten eingegeben haben, wählen Sie OK. Die Daten werden geladen und in das markierte Diagramm eingefügt.
Nun sollten noch die Achsen wie gewünscht skaliert werden. Die Blickrichtung auf das Wasserfalldiagramm kann mit der Maus eingestellt werden. Dazu positionieren Sie den Mauszeiger in dem gelb ausgefüllten Handle der rechten oberen Ecke und verschieben die Ecke entsprechend. Die Farbfüllung unter den Kurven kann über die Funktion Daten=>Weitere Daten-Funktionen=>Wasserfall-Daten-Konfiguration geändert werden.
Mehrkanal-Import¶
Um mehrere Kanäle aus einer Messdatendatei zu importieren, wählen Sie die Funktion Datei=>Weitere Datei-Funktionen=>Wasserfall-Multi-Kanal-Import und wählen die Datendatei aus. Danach wird der folgende Dialog angezeigt:
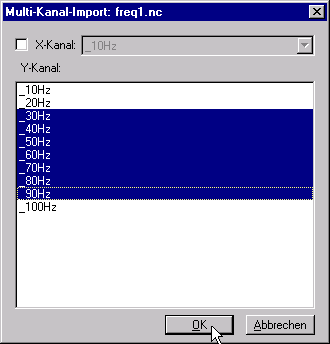
Wählen Sie die gewünschten Kanäle aus der Liste aus. Falls erforderlich kann ein Kanal für die X-Koordinaten ausgewählt werden.
id-711882